

Completing the Genome Puzzle

Armed with cutting-edge technologies, scientists have assembled the first-ever gapless sequence of the entire human genome, providing new DNA puzzle pieces for precision medicine to probe.
After more than a decade of research and nearly US$3 billion dollars, scientists triumphantly announced the sequencing of the human genome in 2003. Since then, the landmark Human Genome Project (HGP) has ushered in a new era in biology and medicine, helping researchers around the world diagnose diseases and discover urgently needed cures.
While this iteration of the human genome was considered as complete as the technologies of the time could allow, some segments had in fact been left unassembled. Despite some additions from later sequencing efforts, the reference currently used by researchers around the world still lacked about eight percent of the genome.
.jpg)
Nearly two decades after the first draft, scientists have now filled in the blanks and completed the sequencing of the human genome in its entirety1.
A puzzling set of patterns
The genetic code contains just four chemical ‘letters’ or bases: A, T, C and G. Simple as this alphabet may seem, their combinations are sufficiently complex to instruct the production of thousands of proteins. Inevitably, this also gives rise to a lot of repeating patterns, such as a lengthy string of A’s or a stretch of ‘CGCGCGCG’ in certain parts of the genome. Such long, convoluted segments are not so easily deciphered, eluding the capabilities of the sequencing technologies used by HGP scientists.
At the time, state-of-the-art sequencing involved cutting up the human genome into small chunks and integrating them into special DNA molecules called bacterial artificial chromosomes. This method was efficient and low-cost thanks to the rapid speed at which bacteria multiply, allowing the human DNA fragments to be cloned, read out and later reassembled to form the genome.
Efficiency, however, came at the expense of sequencing length, with each segment limited to only a few hundred bases. Like fitting together puzzle pieces based on their edges and curves, the short DNA fragments were aligned and connected according to the overlapping ends of their sequences. This method worked well for reconstructing the majority of the genome, but found little success in regions with plenty of repetitive patterns.

If the DNA is split at an area where there are lengthy repeats, the puzzle pieces either appear nearly identical or contain long overlapping patterns. It would be next to impossible to tell where one fragment ends and the other begins, highlighting the need for high-accuracy sequencing of longer segments that cover these repetitive parts in one go.
Filling the gaps
Aptly named after the ends of organised DNA structures called chromosomes, the international Telomere-to-Telomere consortium2 quite literally went end-to-end in sequencing the human genome, leveraging two recent developments in long-read sequencing methods—Oxford’s Nanopore technology and Pacific Biosciences’ HiFi reads.
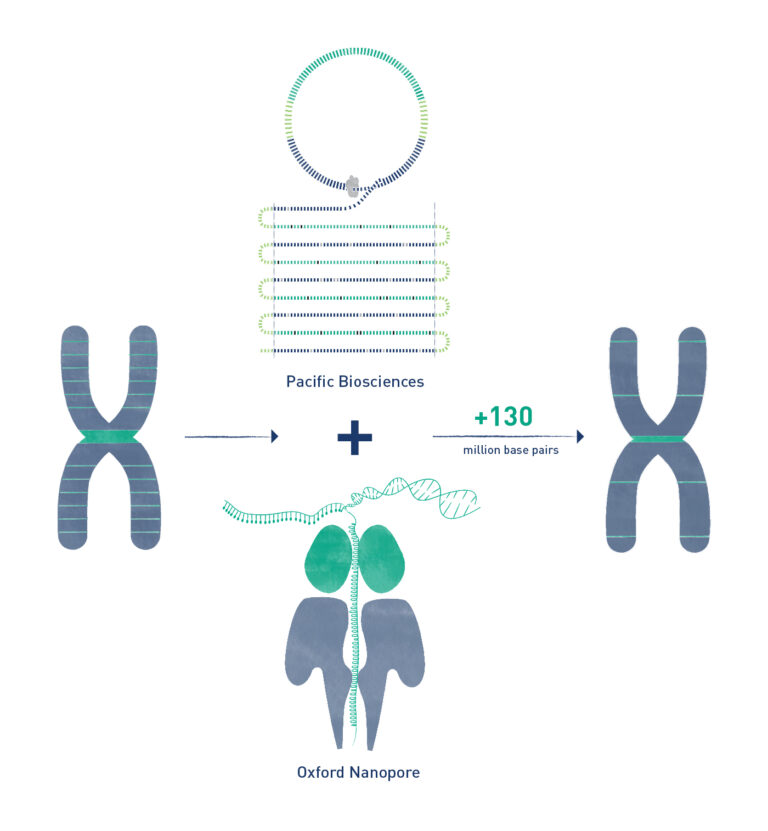
Caption: New DNA sequencing technology from companies like Pacific Biosciences and Oxford Nanopore have enabled scientists to sequence previously missing segments of the human genome. Collectively, they have added 130 million new base pairs, including 115 protein-coding genes.
While reading long DNA sequences may be error prone, HiFi offers unprecedented accuracy by organising the long segments in circular loops and scanning these repetitively. After going around the loop several times, researchers align the copies of these long fragments and tease out any differences in the repetitive regions. Meanwhile, the Nanopore method provides ultralong sequencing of up to a million base pairs. As the DNA segments pass through extremely tiny holes, electrical signals are fired to pinpoint their identity, one base at a time.
In tandem, these technologies enabled scientists to sequence long, identical repeat segments as well as differentiate copies that had subtle variations in their sequences. Moreover, their feat showcases the precise assembly of an entire genome from scratch, without requiring an existing reference standard.
Unlocking more secrets
In the complete genome, the number of sequenced bases now stands at 3.05 billion, with the addition of 130 million new base pairs, including 115 protein-coding genes. The rest of the bases, meanwhile, are noncoding regions, which do not encode for genes but may be involved in gene regulation. This comes as little surprise, as it reflects what is already known about the human genome, where only 2-3 percent contain instructions for protein synthesis.
According to previous studies, many noncoding sequences have shown important regulatory activities involved in complex disease. Whereas the coding portions dictate the proteins to be produced, the noncoding regions control whether those genetic instructions are even read, analogous to controlling whether a gene is turned ‘on’ or ‘off’. The newly sequenced noncoding segments could hold similar functions.
Now that scientists have overcome the technological barriers that left gaps in previous genomic sequences, variations across the entire genome may soon be mapped among different populations.
At the exciting frontiers of precision medicine, such genomic sequencing would be key to investigating the differences between healthy versus sick cells or comparing patients from different demographics such as ethnicity and age groups. Additionally, more clues remain to be uncovered on the complex relationship between genetics and external factors like diet and the environment—setting the difference between high or low disease risk, severe or mild symptoms, and strong or weak responses to treatments.
When the human genome was first drafted, scientists quickly developed advanced tools to analyse those sequences and figure out their corresponding activities. With the final eight percent of the genome now sequenced, these technologies are similarly poised to accelerate scientific discoveries about their functions and implications in health and disease.
References:
1 Nurk, S., Koren, S., Rhie, A., Rautiainen, M., Bzikadze, A.V., et al. The complete sequence of the human genome. bioRXiv 445798 (2021).
2 Telomere-to-Telomere consortium. https://sites.google.com/ucsc.edu/t2tworkinggroup